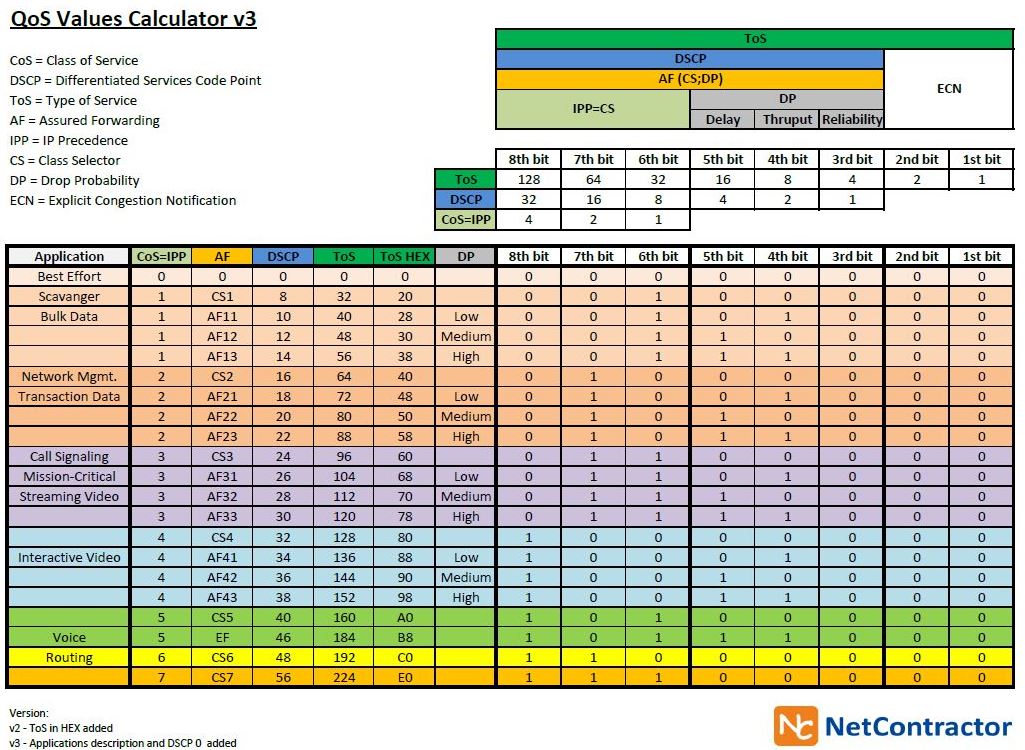
very nice feature IF your routers can handle it. you can use “ping -Q 0xB8” for testing VoIP traffic, or iperf.
important values are either 00h (default, best effort), or B8h (expedited forwarding, good for RTSP), and 68h (AF31, for SIP) – when ECN is set to 00 binary!
this table here sums it up very nicely:
July 1st, 2023 in
hardware stuff,
software stuff |
Comments Off on DSCP and ECN
Folks plug in their devices, fridges, web/security cams, toasters, … BUT it seems (almost) noone has ever heard of bandwidth management. sure, it’s a bit complicated, and one needs to know their (paid-for) bandwidth, needs for certain devices, protocols etc – but when a webcam or a fridge has full gigabit access in&out that worries me. just gotta mention mirai and DDoS, and you see why it’s important. most people however do not want to pay more for any advice, they just goto frys, bestbuy, costco etc and pickup cameras, and expect everything to magically work. thanks to DHCP it does, many times, but one day they’ll find out WHY there are IT folks that actually take the time “to read the manual” (and hopefully get some $ for it) …
IF you don’t have time to study bandwidth management the easiest thing to do is switch the ports from “auto” mode down to 10Mbps or 100Mbps – so your cam has enough bandwidth but not more than the peak needed – the rest could be used for malicious purposes!

April 12th, 2018 in
hardware stuff,
software stuff |
Comments Off on IoT = Internet of Things not configured correctly
tried the e10s mode out since a few weeks ago, mostly positive results
a few thing sometimes don’t work right, but then, it’s an alpha version i’m using, so that’s expected risk
you can always open a non-e10s window
December 17th, 2014 in
software stuff |
Comments Off on fire fox
HP was once a great company. their products lasted forever, were high priced but worth their money. every penny. then they bought compaq (after they choked after their digital purchase). whatever. they needed to cut costs, and therefore product lines. cheap compaq lines like ‘presario’ were rebranded as HP. useless crap. cheap chipsets from SIS, very little updates & support. they deserved to be oblivious. the only good products they make today are their server lines.
however, i still love HP. they have given birth to my ‘HP laserjet’. the thing does not even have a model number. it’s ONE. after that the laserjet TWO came out, a big success. but the ONE was groundbreaking, breathtaking, everlasting, reliable, goodwilled, cheap-to-use … i can go on longer. the thing prints 8 pages a minute, crisp, in courir since it has only 128MB RAM. whatever. it works. it’s almost 30 years old. it works. HP quality…. from back-then.
but now i hate HP, at the same time. i have a mid-priced inkjet ‘officejet-pro’, which, as a ‘pro’, i had great hopes for the machine. turned out a 5 cent piece of electric tape made it work again …. after HP tried to rip me off, and force me to buy another color cartridge. for $30.
i don’t print color. i don’t need to. i don’t want to. if i need pictures, i go to costco, or savon. i print ONLY BLACK. everything in the system and the driver is set to ” BLACK ONLY”. so why do they want me to buy color cartridges??? to preserver printhead health? i care less. i print ONLY BLACK. did i say thay before?
put a piece of electric tape in front of the oval window of the bladder inside the cartridge – then the sensor can’t see that it’s empy. maybe your printhead dies. maybe the printer dies. whatever. i print ONLY BLACK.
my HP laserjet still works. if that inkjet ever dies, i just go back to my 30 year old HP printer, and smile, while i’m feeling the nice warmed up pages coming out of it. i love HP.
November 30th, 2013 in
Uncategorized |
Comments Off on HP
think stacking chips, 3D memory, MLC memory etc – you will NOT get to the highest performance since you are still left with interconnects that go thru several solder points, traces on PCBs, fiber optics etc. that will be the biggest bottleneck you have – transmitting the data to an adjacent device
consider putting all CPUs, cache, memory on one 12 inch wafer. that’s a few hundred billion transistors with todays tech. then interconnect two wafers with a PCB in the middle like a sandwich, that reaches out on the sides to offer space for network and power, and cool the whole thing with a liquid – you will need to use liquid since you have a great power density
with sophisticated algorithms you need to lock out (and disconnect power) from CPUs and memory that is damaged, or run those with lower frequencies or capacities, most likely the outer diameters of the wafer (since the target angle here during UV processes is unfavorable). so just group slow dynamic RAM on the outside, and all CPU in the center, surrounded by cache and interconnects. leave the “dead” components there but with no power – their surface will help cool down the adjacent working devices anyways.
it will not get more dense than that – unless you use via’s thru the wafer and sandwich dozens of layers, but how will you cool that? small holes or channels for liquid in between the layers … there are some solutions but for today the sandwich with 2 wafers is the fastest way to get HPC right now
April 24th, 2013 in
hardware stuff |
Comments Off on todays only way to HPC
this is for old fashioned mechanical harddisks obviously, they will be around for quite some time
when reading a fragmented disk you should first get all the positions of the data, and then sort by cylinder number, then start reading from the outside inwards w/o searching, just track-to-track operations since those are done within a milisecond
the disks should not be idle – they have to be either read, fill a cache, write, search sector/cylinder, defrag, encrypt, compress etc
it’s OK to read/write out-of-band sectors when it’s faster to do so
why can’t a disk controller compress data? or defrag data? or de-dupe data?
it’s slower than the host, but they got all day, and unless it’s a busy server they are idle most of the time, and have now 64+ Mbyte cache, and must handle 1 Gbit/s and more throughput, so there seems to be some processing capacity
January 1st, 2013 in
hardware stuff,
software stuff |
Comments Off on disk access
since new disks exceed the old sector / heads / cylinder specs the makers have resorted to this “cheat”:
sec = 255
heads = 63
always, which is the max the parameters allow, and you vary the cyl number to increase its size (e.g. 243201 cyl for a 2000GB disk)
now this leads to having the first user sec (after the bootsector, number zero!) to be at 255 x 63 sectors on cyl 1 => sector 16065 , which is NOT a multiple of 8, therefore NOT aligned, and all that follows is slow access
move the beginning to the 64th sector, and the first partition starts at 255 x 64 => sector 16320 (which is 8 x 2040 ), and use for partitions’ cylinder count a multiple of 8
(that’s a “math cheat” to ensure the sector number will always be divisible by 8, since “anynumber x anothernumber x 8” will always be divisible by 8)
in my case a WD20EARX the write speed went from 43MBs to 76MBs, read from 64MBs to 72MBs for a contingous 2GB file – wth an old PCI-SATA150 controller
most important in all of this is that a filesystem cluster (4k size with NTFS, and ext3 linux) fits perfectly inside a physical 4k unit on the disk – and even when you still use 512 byte sectors once it’s aligned that improves speed, since you read 8 of those in one go
December 31st, 2012 in
hardware stuff |
Comments Off on advanced format, aligned
needs three different passwords implemented:
1 for normal user access
2 to delete everything, or corrupt records in ways that are not recoverable
3 limited access for people nosing around, to satisfy investigators and stop torture etc
December 29th, 2012 in
Uncategorized |
Comments Off on true crypt
this one was really annoying – and it existed since 2008 at least!
i’m using ubuntu for some of my servers, and an old one on 10.04.4 with a 845G always showed UDMA33 mode caused by 40 wire cable
this fixed it:
edit /etc/grub/grub.cfg
after the line for the kernel add behind it (in the same line)
libata.force=1.00:80c,2.00:80c
that forces UDMA for 80 wire cables, whatever the chips and disk can handle
November 8th, 2012 in
hardware stuff,
software stuff |
Comments Off on bugs
… sounds like a lot. if you look back at the last 30 years it’s really amazing what has changed in terms of storage capacity and speed. now think about the next 100 years. scientists say we will not be able to keep up with moore’s law (to double capacity/speed every 18 month), but there’s always something new coming out, new materials, new ideas.
however what i see often is certificates (private keys, code signing etc) that have a 100 year life. no system will survive that long, and if you upgrade you’ll get a new SSL or TLS certificate etc. some old files you’ll keep though, and there’s the danger. you give away old servers, old disks etc but then some numbers like your SSN or your birthdate stay the same for many years. there is a chance too that you’ll get hacked, or one of the companies you do business with.
many cracking or hacker attempts though would be easily prevented IF we would use ‘expiration dates’ more thoughtful. what seems secure today might be the joke for brute-force-attackers in 5 years from now. just set a realistic expiry date for your certs!
January 16th, 2012 in
Uncategorized |
Comments Off on 100 years in IT …